Introducción
Hace tiempo que quería subirme al tren de los LLM y aprender a usar uno de los frameworks más populares. Hace unos meses, vi una excelente presentación en Cisco Live de mi buen amigo Jesús, y eso me dio la determinación que necesitaba para finalmente profundizar en el tema.
Desde entonces, he estado investigando y pensando en un buen caso de uso que pudiera servir como objetivo para mi proceso de aprendizaje. Después de considerar diferentes opciones, decidí construir un asistente de IA para SD-WAN que pudiera ayudarme a solucionar problemas relacionados con esta tecnología. Aprovechando las herramientas disponibles, decidí que mi asistente sería un experto en la funcionalidad de Network Wide Rath Insights.
En esta publicación, quiero compartir un poco de mi experiencia para construirlo y, por supuesto, mostrar algunos de los resultados. Para entenderlo mejor, sugiero tener el repositorio de Github abierto y consultarlo a medida que avanzas por la publicación.
Sobre la configuración
Mi laboratorio SD-WAN está corriendo la versión 20.12.3 y WAN edges están utilizando 17.9.4a. Tengo una topología muy simple:
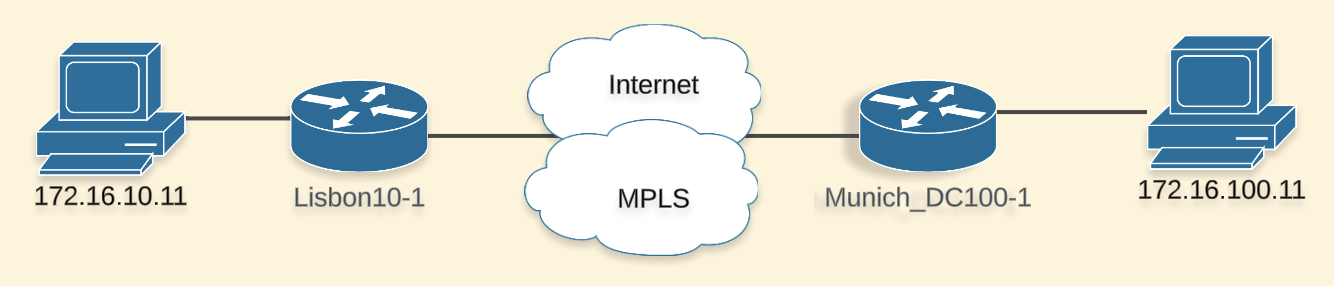
El lenguaje de programación utilizado es Python y el framework que elegí para interactuar con el LLM es Langchain. Utilicé OpenAI Model GPT-4o y un bot de webex para la interacción. El repositorio se puede encontrar aquí.
Mi objetivo
Para dar contexto, la solución de problemas dentro de una infraestructura SD-WAN no es sencilla debido a que el tráfico está cifrado, las políticas dictan cómo fluirá el tráfico, pueden existir múltiples caminos hacia un destino, los siguientes saltos pueden cambiar según las políticas, hay múltiples saltos involucrados, entre otros factores. Determinar toda esta información lleva tiempo y no es un proceso directo.
NWPI Trace es una herramienta que mejora significativamente el proceso de troubleshooting, ya que proporciona información y visibilidad salto a salto. Se puede iniciar fácilmente desde la interfaz del Manager, detecta flujos según filtros especificados y permite explorar la red para obtener toda la visibilidad necesaria. Es una herramienta muy completa y avanzada.
Como mencioné antes, quería utilizar este proyecto como un campo de prueba para aprender, y dado que no tenía experiencia previa con LLMs o LangChain, establecí un objetivo sencillo:
Construir un asistente que pueda iniciar una traza NWPI y darme detalles de los flujos
Planificación y construcción
Ok, tengo mi objetivo, pero ¿cómo comienzo?
Tomé un enfoque práctico que significaba que no aprendí Langchain desde cero y en su lugar tomé el repositorio de la sesión de Cisco Live como base y construí sobre eso. Las razones para elegir este repositorio fueron simples:
- Se explicó en las sesiones, así que tuve una idea general de las tecnologías y su propósito.
- Pensé que sería fácil ajustar a mi caso de uso (por ejemplo, también uso webex, interactuaré con dispositivos de red, vi cómo las herramientas podrían reemplazarse con la mías)
Tuve que limpiar un poco antes de comenzar, esto me requirió que entendiera lo que era esencial para hostear el LLM e interactuar con él. Afortunadamente, el repositorio tiene una estructura organizada que facilita la comprensión.
De la sesión, aprendí sobre [Langchain Tools] (https://python.langchain.com/v0.1/docs/modules/tools/), así que sabía que podría crear funciones que mi agente podría usar para realizar diferentes acciones. En este caso, las acciones serían algo así como comenzar trazas y leer la información obtenida.
Desafío 1
Necesitaba familiarizarme con la APIs de NWPI. En este punto, sabía que en algún lugar de la documentación de la API había visto que algunas operaciones estaban disponibles, pero nunca me había tomado el tiempo de analizarlas en detalle. Para mi sorpresa, las acciones específicas de iniciar un trace y obtener sus detalles no estaban incluidas… En su lugar, encontré información sobre cómo iniciar una “tarea” o “Auto-on Task”, que no es lo mismo que el “Trace” que tenía en mente.
En este punto, tenía que decidir si seguir el camino “oficial” (quizás más fácil) o explorar una alternativa para lograr exactamente lo que quería.
Sabiendo que casi todo en SD-WAN es impulsado por APIs, usé la pestaña de inspección de mi navegador y comencé a explorar las APIs que se activaban cuando iniciaba un trace desde la UI. Después de una primera revisión rápida, determiné que era factible y comencé a recopilar la información que necesitaba.
Desafío 2
Ya sabía que tendría que hacer algo de análisis para convertir mi idea en realidad, pero subestimé cuánto tendría que hacer. De hecho, la dificultad de esta tarea me alejó del proyecto por un tiempo, ya que se volvió cada vez más compleja.
En mi mente solo había 3 tareas “simples”:
- Encontrar la API para iniciar el trace
- Encontrar la API para confirmar que el trace está en ejecución
- Encontrar la API que me dé detalles de los flujos
API para iniciar la traza
Iniciar la traza desde la interfaz de usuario es muy sencillo, solo necesitas un Site ID y un VPN ID. Sin embargo, hay verificaciones subyacentes que damos por sentadas.
- El Site ID realmente es necesario para identificar los dispositivos en los que iniciar la traza
- Hay una serie de opciones (informes de QoS, visibilidad ART, visibilidad de aplicaciones, DIA, etc.) que dependen de la versión
- La VPN debe existir
Para realizar esto, creé la función get_device_details_from_site para poder encontrar la información relacionada con los dispositivos en los que iniciar el trace. Necesitaba:
- versiones
- números de serie
- nombres
- estado de conectividad
Luego, creé la función start_trace que recibiría la información obtenida previamente y otros filtros. Mantuve los filtros lo más simples posible, dejando solo la opción de especificar una subred de origen y destino. Hay muchas opciones para la traza para las cuales no realicé ninguna verificación de versión antes de ejecutarla, solo lo hice para los informes de QoS, que requieren la versión 17.9 o posterior. Esta función devuelve información necesaria más adelante para verificar el estado.
API para confirmar que la traza se está ejecutando
Esta fue probablemente la tarea más fácil. Creé la función verify_trace_state y con la ayuda del LLM se puede ejecutar unos segundos después de comenzar la traza. Devuelve el estado, que también es necesario para obtener información más adelante.
API para darme detalles de los flujos
Esta fue la tarea más compleja y tardada. En mi mente, verificar el resultado de una traza es muy simple, sin embargo, cuando recibimos la información en pedazos, a través de diferentes llamadas comienza a ser complicado.
Intenté replicar el proceso que sigo en la interfaz de usuario:
- Ver las estadísticas del trace y comprobar los flujos que fueron capturados (si es que hay alguno).
- Para la lista de flujos, buscar el que tiene el botón “readout” en rojo (problema detectado) y hacer clic para obtener más detalles.
- Expandir la vista del flujo para acceder a las funcionalidades avanzadas y así determinar las características por las que el paquete pasa en cada uno de los saltos.
Para obtener los flujos capturados en el trace, creé la función get_flow_summary. Esta función devolverá la lista de los flujos capturados. Verás detalles como origen/destino, aplicación y protocolo. Esto es útil para identificar el flujo cuyo id te interesa para obtener más detalles.
Creé la función trace_readout para obtener un resumen de los eventos que el trace capturó junto con el camino afectado. Por ejemplo, podrías ver que un flujo SSH no está funcionando entre el Dispositivo X y el Dispositivo Y.
Una vez que hayas identificado el flujo y los eventos que te interesan, puedes obtener información detallada del flujo con la función get_flow_detai. Esto te proporcionará información como:
- Hops
- Eventos
- Colores locales/remotos
- Interfaces de entrada/salida
- Funcionalidades de entrada/salida aplicadas a los paquetes
- Funcionalidad que determina decisión de ruteo
Con esta información es posible ver todo tipo de cosas, como ACLs, tipo de políticas aplicadas, por qué un paquete fue enviado a través de un color específico, caídas, confirmar que tu política está funcionando como se espera, etc.
Ok, creo que eso es todo
Demo
Comencé creando un ACL para bloquear la comunicación y la apliqué en el lado de DC.
Munich_DC100-1 - ACL configuration
sdwan
interface GigabitEthernet2
access-list ACL_Drop_172_16_10_0 out
policy
access-list ACL_Drop_172_16_10_0
sequence 1
match
source-ip 172.16.10.0/24
destination-ip 172.16.100.0/24
!
action drop
count dropCounter
!
!
default-action accept
!
¿Mi asistente detectará esto? 🤔
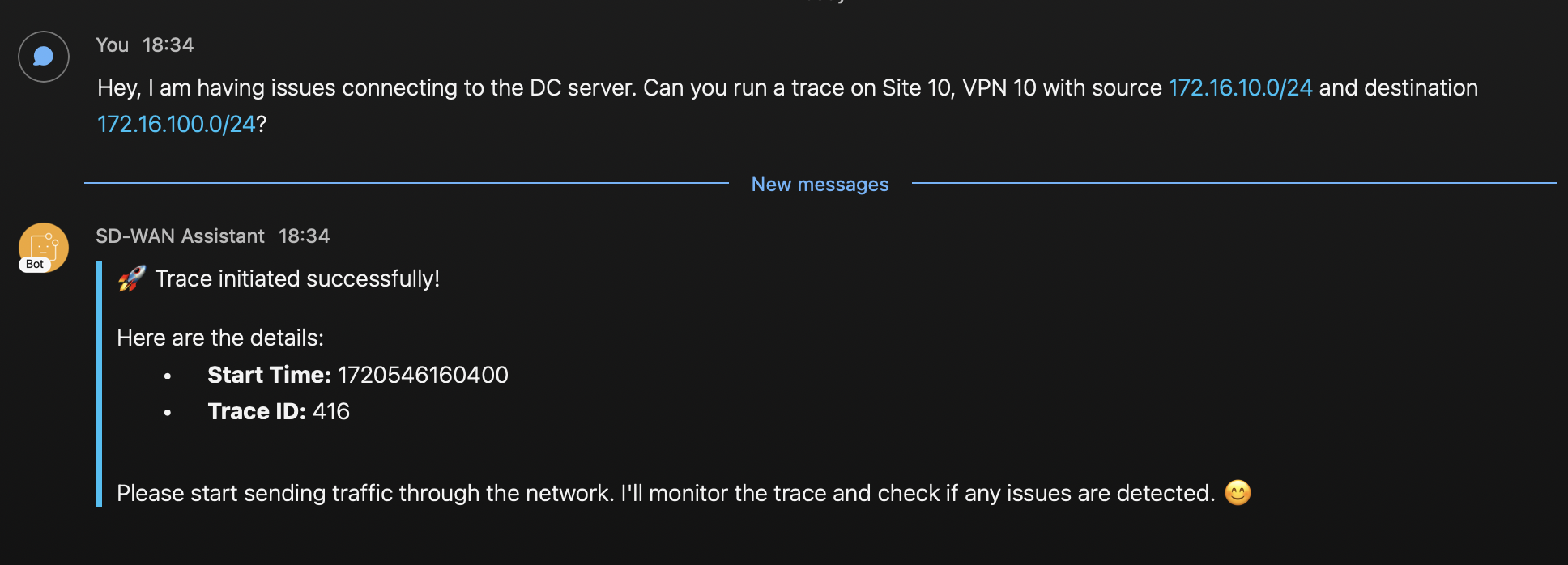
A continuación, comienzo la aplicación y solicito que el LLM inicie una traza. Puedo confirmar en la UI que se crea.

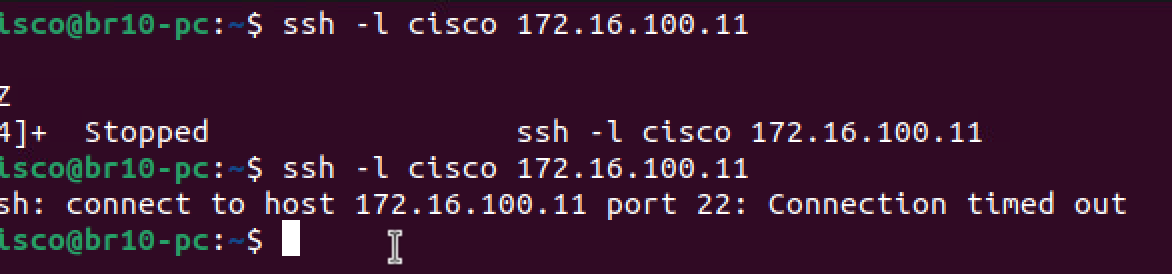
Lanzo un par de conexiones SSH de Branch a DC
Después, le pregunto al asistente si se han capturado flujos, responde con esto
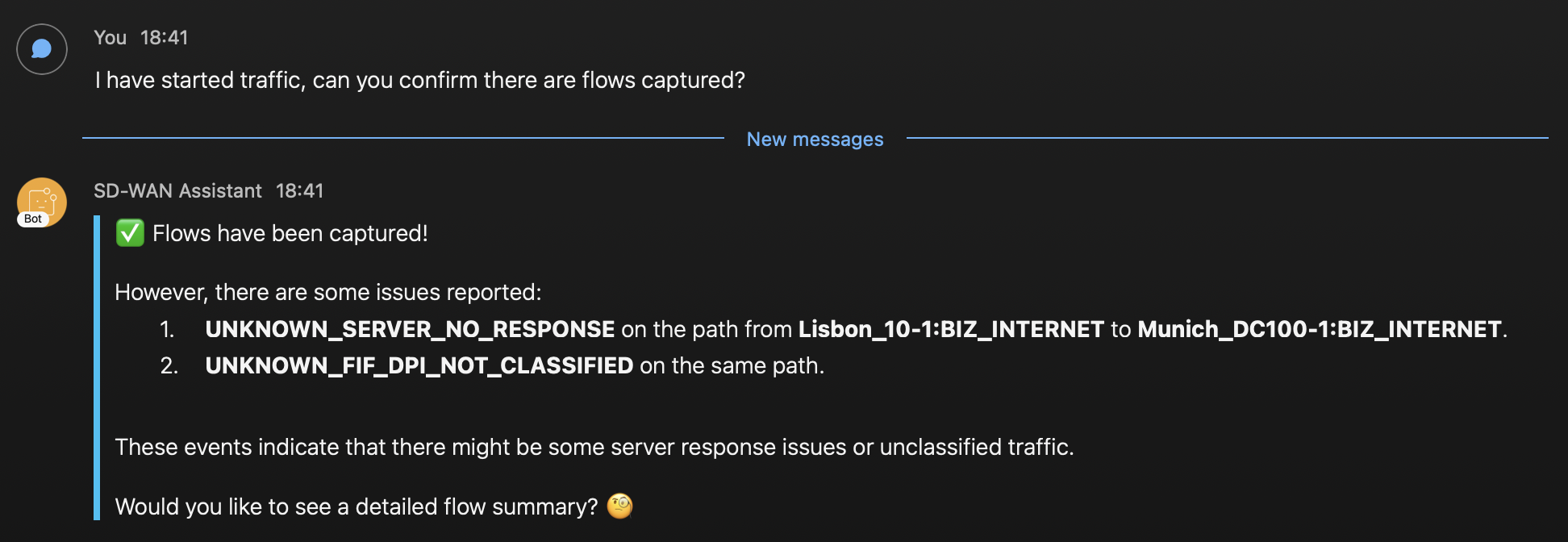
Podemos ver que los flujos fueron capturados y también me dio más información sobre los eventos detectados y el camino que tomaron los paquetes incluyendo los nombres de los dispositivos. El primer evento parece estar relacionado con nuestro problema. Hasta ahora, la información parece precisa, voy a pedir más detalles.
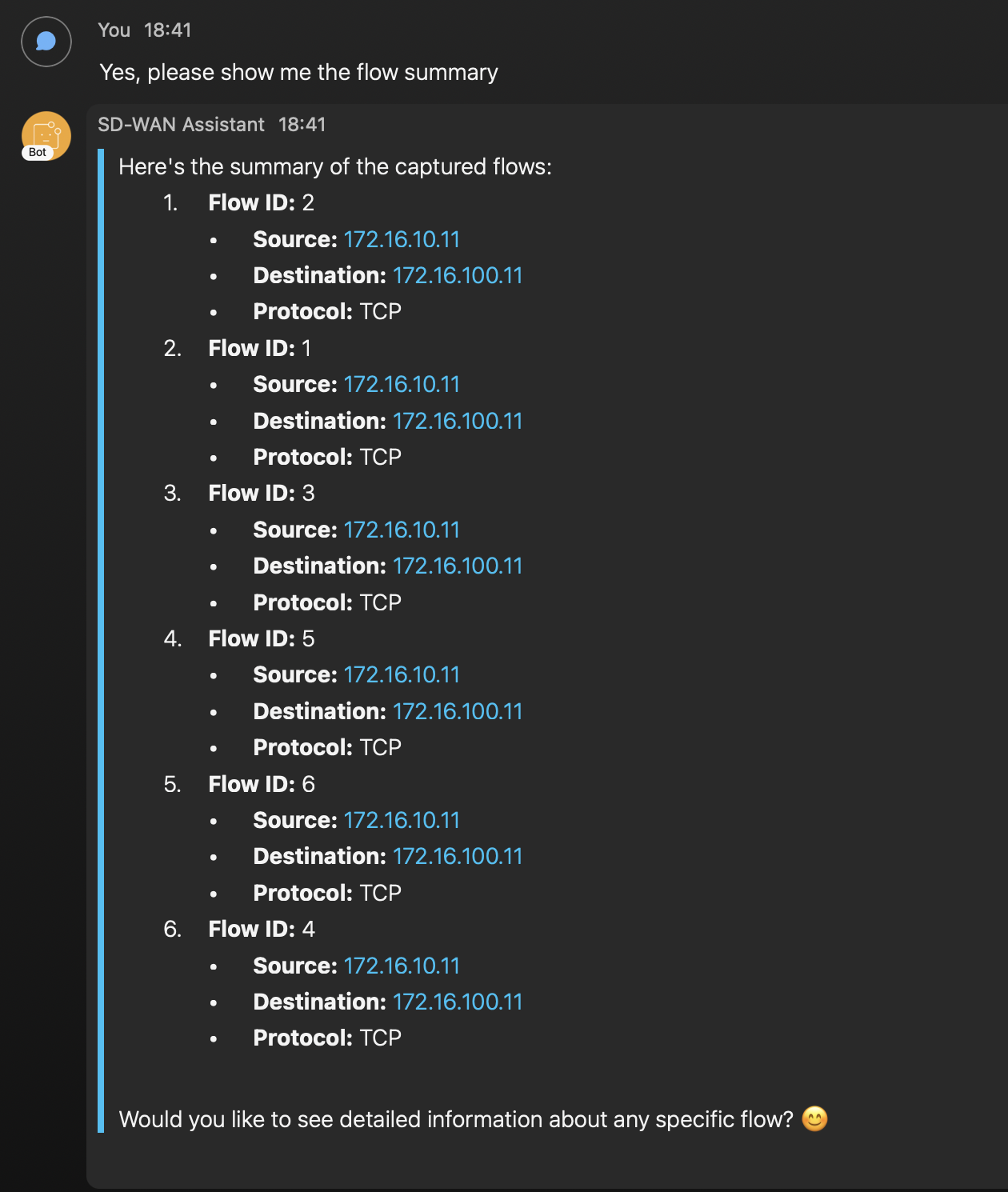
Con esto, podemos ver que el cliente envió múltiples intentos de SSH, podemos profundizar en uno de los flujos. Veamos qué más da.
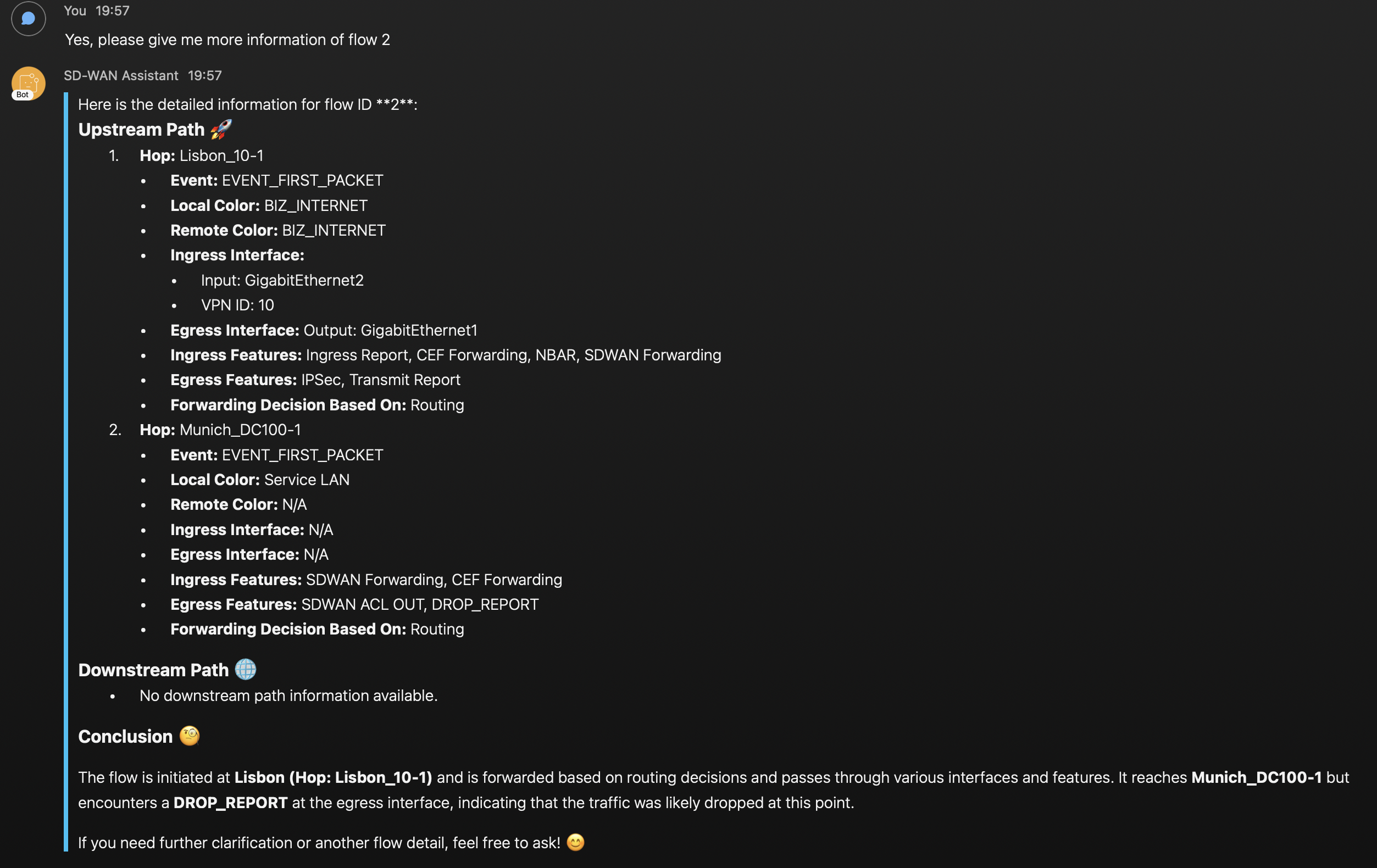
Finalmente, el asistente proporciona información detallada sobre las funcionalidades que se aplican a cada uno de los flujos. En el segundo salto, en Munich DC, podemos ver que las funcionalidades de salida muestran el SD-WAN ACL y un ‘Drop Report’. El asistente proporciona su propia conclusión y también sospecha que el router de Munich está tirando el tráfico.
Con un poco más de trabajo, el agente podría decir el nombre del ACL y el número de secuencia responsable de tirar el tráfico. ¡Hemos identificado con éxito la raíz del problema! 😀 🎉
Lecciones aprendidas
- Cuando comencé, quería ser súper cauteloso con los créditos ($$), así que estaba usando GPT-3.5-Turbo-16k que es más barato pero también menos inteligente. En algún momento, enfrenté problemas con el LLM entrando en un loop, decidí probar GPT-4O y sentí una diferencia en la forma en que el agente estaba razonando.
- Inicialmente, estaba usando una temperatura LLM = 0, esto estaba bien, pero las respuestas carecían de variedad y detalles, necesitaba hacerlo más hablador. Ajustar la temperatura = 0.9 me dio un buen equilibrio entre la charla y la corrección (aunque a veces el agente todavía proporciona información que es cuestionable en función de las salidas)
- Hacer troubleshooting puede ser difícil a veces, principalmente me basé en imprimir los resultados de las funciones mientras estas se ejecutaban y el agente imprimía en la terminal. Esto me permitió entender qué herramientas estaba utilizando el agente y el orden en que las utilizaba. Además, pude ver qué estaban devolviendo esas herramientas. Aquí tienes un ejemplo:
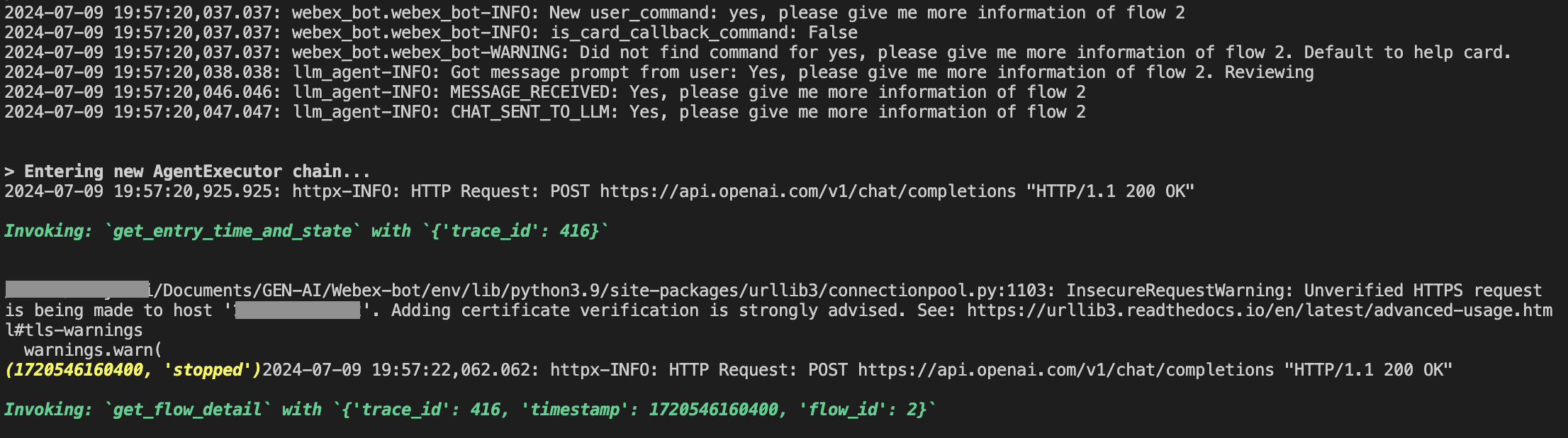
El texto en verde indica las herramientas a las que está accediendo al agente. El texto amarillo es la información devuelta por una función. En este caso, podemos ver que el agente llamó la función "get_entry_time_and_state" para que obtener información necesaria para llamar a la siguiente función "get_flow_detail"
Hay mejores herramientas disponibles para ayudar con la resolución de problemas como LangSmith Tracing, lo voy a explorar en el futuro.
- El prompts de mi agente tuvo que ser refinado varias veces, a menudo me di cuenta de que necesitaba proporcionar más detalles para manejar ciertas situaciones correctamente, especialmente cuando la salida de una función era necesaria para llamar a otra o para manejar situaciones inesperadas. Creo que aún puede mejorarse, de hecho, quiero escribir un prompt completamente diferente para intentar hacer que el agente ejecute todas las herramientas por sí mismo y solo devuelva una conclusión después de analizar todas las salidas.
Conclusión
En general, fue un buen y largo ejercicio de aprendizaje esto de construir mi primer asistente. Me siento contento con el resultado, ya que logré alcanzar mi objetivo. Al mismo tiempo, reconozco que hay muchas cosas que se pueden mejorar para hacer que los resultados sean más confiables y significativos. Además, hay mucha más información que NWPI puede mostrar, por lo que las herramientas definitivamente se pueden ampliar.
Como siguiente paso, planeo aprender LangChain adecuadamente y entender cómo puedo implementar múltiples agentes para mejorar la funcionalidad y confiabilidad de mi asistente.
¡Espero que este post te ayude de la misma manera que la presentación de Cisco Live me ayudó a mí!