Introducción
La idea de escribir esta publicación surgió tras presenciar un comportamiento inesperado en cómo los routers SD-WAN manejan diferentes operaciones que provocan un reinicio del router. De hecho, esto se descubrió “por accidente” al realizar actualizaciones de software en un par de routers SD-WAN y no fue detectado durante pruebas de failover. En la publicación de hoy voy a comparar cómo se trata un reinicio usando el comando reload en comparación con uno provocado por una actualización de software.
Topología
Una configuración SD-WAN tradicional con doble router, corriendo BGP hacia un router externo en el lado del servicio que proporciona conectividad a otros sitios. Algo simple como esto:
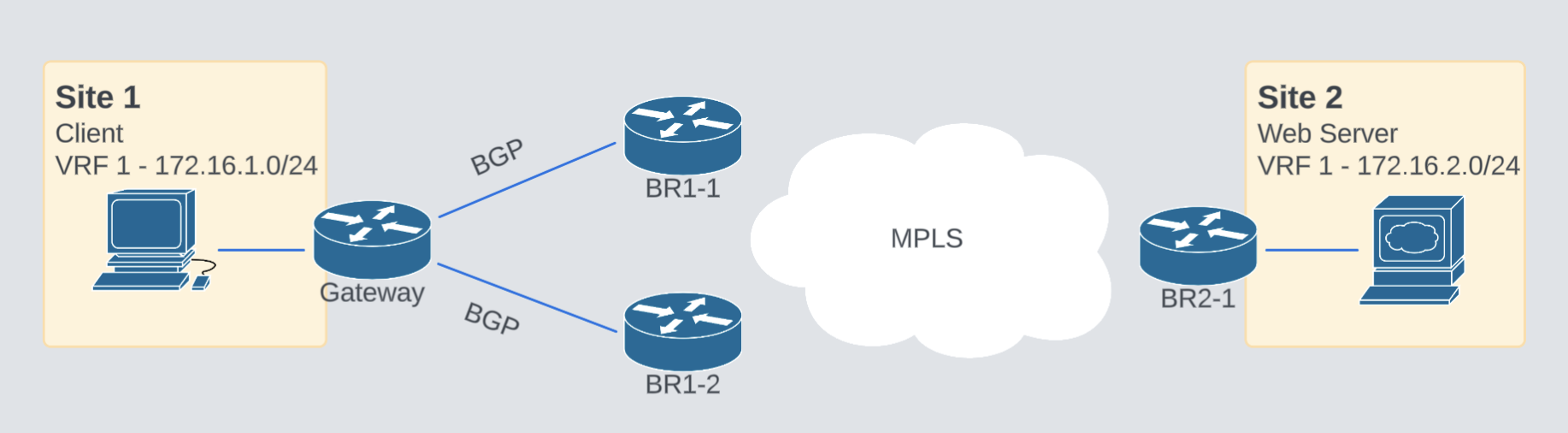
La configuración de BGP es súper simple y suficiente para ejemplificar este comportamiento. Los routers SD-WAN tienen configuraciones idénticas.
Gateway#show run | s r b
router bgp 64002
bgp log-neighbor-changes
neighbor 172.16.1.1 remote-as 64001
neighbor 172.16.1.2 remote-as 64001
BR1-1#sh run | s r b
router bgp 64001
bgp log-neighbor-changes
!
address-family ipv4 vrf 1
network 172.16.2.0 mask 255.255.255.0
neighbor 172.16.1.15 remote-as 64002
neighbor 172.16.1.15 activate
neighbor 172.16.1.15 send-community both
distance bgp 20 200 20
exit-address-family
A nivel de enrutamiento, el router Gateway tiene dos rutas disponibles para llegar al servidor web, ambas iguales y aprendidas por BGP. Con la configuración actual, el Gateway elige BR1-1 como ruta principal y BR1-2 queda como respaldo.
Gateway# sh ip route | b Gateway
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Ethernet0/0
L 172.16.1.15/32 is directly connected, Ethernet0/0
B 172.16.2.0/24 [20/1000] via 172.16.1.1, 02:48:02
Gateway# sh ip bgp
BGP table version is 3, local router ID is 192.168.1.15
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
t secondary path, L long-lived-stale,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
* 172.16.2.0/24 172.16.1.2 1000 0 64001 i
*> 172.16.1.1 1000 0 64001 i
Comportamiento usando el comando reload
Comencemos examinando qué hacen los routers SD-WAN al reiniciar con el comando reload. Reiniciaré BR1-1, ya que es el router primario.
*18:08:35.380 UTC Wed Jul 30 2025
BR1-1#reload
Proceed with reload? [confirm]
Inicio un ping desde el router Gateway para verificar si la conectividad se ve afectada:
Gateway#sh clock
*18:08:42.345 UTC Wed Jul 30 2025
Gateway#ping 172.16.2.2 rep 10000
Type escape sequence to abort.
Sending 10000, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
<...>
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
*Jul 30 18:09:01.490: %BGP-5-NBR_RESET: Neighbor 172.16.1.1 reset (Peer closed the session)
*Jul 30 18:09:01.490: %BGP-5-ADJCHANGE: neighbor 172.16.1.1 Down Peer closed the session
*Jul 30 18:09:01.490: %BGP_SESSION-5-ADJCHANGE: neighbor 172.16.1.1 IPv4 Unicast topology base removed from session Peer closed the session
<...>
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Success rate is 100 percent (10000/10000), round-trip min/avg/max = 1/1/32 ms
Gateway#sh ip route | b Gateway
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Ethernet0/0
L 172.16.1.15/32 is directly connected, Ethernet0/0
B 172.16.2.0/24 [20/1000] via 172.16.1.2, 00:02:42
Gateway#sh ip bgp all sum | b Nei
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
172.16.1.1 4 64001 0 0 1 0 0 00:00:19 Active
172.16.1.2 4 64001 193 197 4 0 0 02:51:15 1
We can see that the BGP session to BR1-1 was closed and the ping continued without issues through BR1-2.Podemos ver que la sesión BGP con BR1-1 se cerró y el ping continuó sin problemas a través de BR1-2.
A nivel de paquetes, BR1-1 cerró la sesión BGP antes de reiniciar, evitando interrupciones.

Este es el comportamiento esperado y cómo se hacen típicamente las pruebas de failover.
Comportamiento durante una actualización
Ahora BR1-2 es la ruta primaria:
BGP#sh ip route | b Gateway
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Ethernet0/0
L 172.16.1.15/32 is directly connected, Ethernet0/0
B 172.16.2.0/24 [20/1000] via 172.16.1.2, 00:28:48
Esta vez usaré el Manager para actualizar BR1-2.
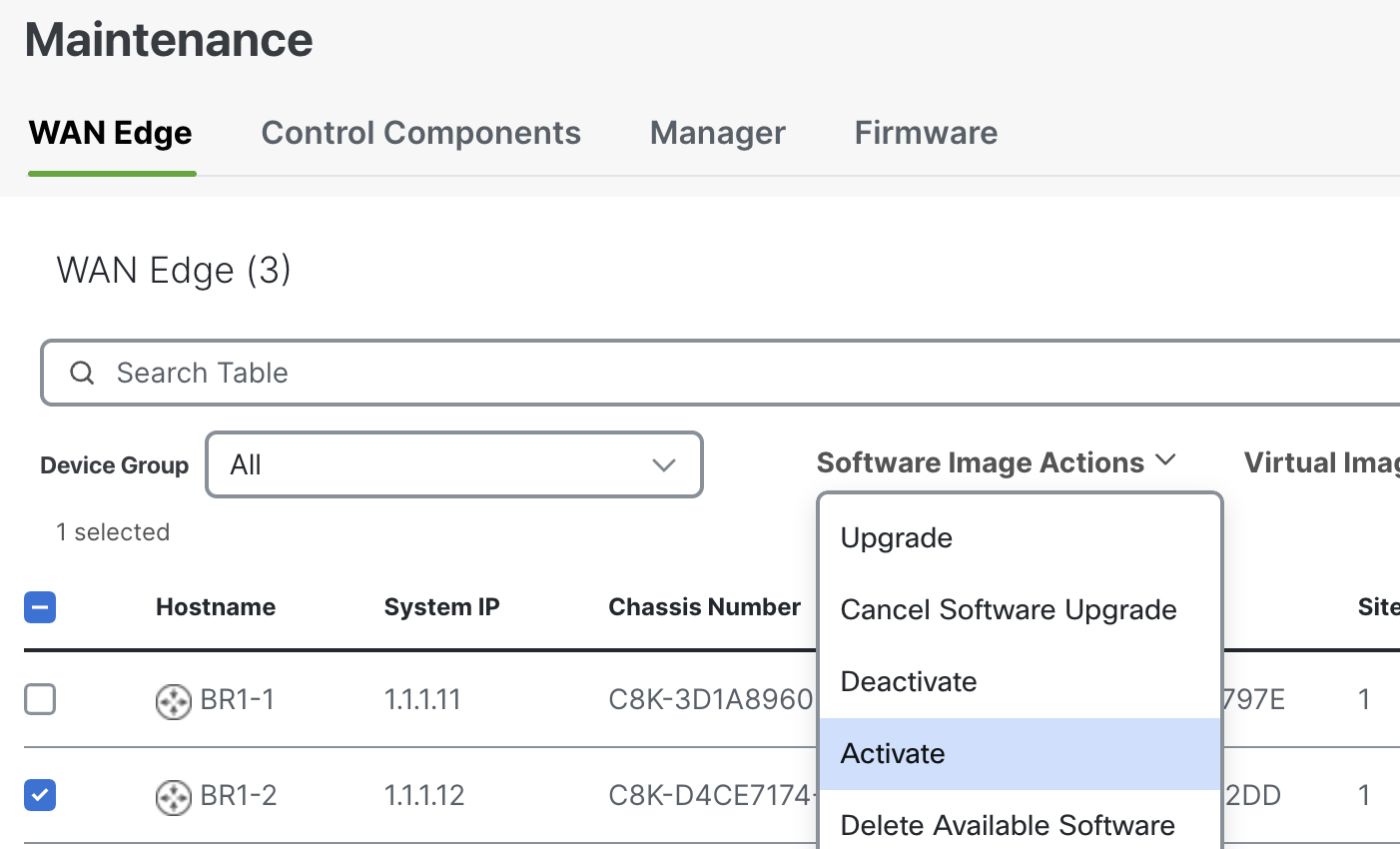
El ping desde el router Gateway falla cuando BR1-2 se reinicia:
Gateway# ping 172.16.2.2 rep 1000000
Type escape sequence to abort.
Sending 1000000, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!............................................
Curiosamente, el vecino BGP sigue activo, y la ruta sigue apuntando a BR1-2 aunque ya no está disponible:
Gateway# sh ip route | b Gate
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Ethernet0/0
L 172.16.1.15/32 is directly connected, Ethernet0/0
B 172.16.2.0/24 [20/1000] via 172.16.1.2, 00:35:09
El tráfico queda en un blackhole durante el tiempo de espera de BGP:
Gateway# ping 172.16.2.2 rep 5
Type escape sequence to abort.
Sending 10, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
.....
*Jul 30 15:17:10.575: %BGP-3-NOTIFICATION: sent to neighbor 172.16.1.2 4/0 (hold time expired) 0 bytes!!!!!
Success rate is 50 percent (5/10), round-trip min/avg/max = 1/1/2 ms
*Jul 30 15:17:10.575: %BGP-5-NBR_RESET: Neighbor 172.16.1.2 reset (BGP Notification sent)
*Jul 30 15:17:10.575: %BGP-5-ADJCHANGE: neighbor 172.16.1.2 Down BGP Notification sent
*Jul 30 15:17:10.575: %BGP_SESSION-5-ADJCHANGE: neighbor 172.16.1.2 IPv4 Unicast topology base removed from session BGP Notification sent
Gateway#ping 172.16.2.2 rep 5
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/3 ms
Conceptos erróneos comunes
Un error común en operaciones de red es asumir que todos los tipos de reinicio se comportan igual. Es fácil pensar que si el reinicio se da por CLI, por algun power cycle o una actualización de software, el resultado será consistente: BGP se cae, se quitan rutas y se hace el failover. Este estudio demuestra lo contrario.
En Cisco SD-WAN, un reinicio por actualización desde el Manager no cierra las sesiones de control como BGP. A diferencia del comando reload, no se envía un FIN de TCP que cierra la sesión de manera correcta. El reinicio por actualización de software se salta este paso, manteniendo la sesión “viva” aunque el router vecino este abajo.
Este comportamiento sutil rara vez está documentado, y se prueba aún con menos frecuencia. Muchos ingenieros confían únicamente en pruebas de reinicio o flapeo de interfaces para validar el comportamiento ante fallos. Como resultado, pueden creer que su configuración es resiliente, cuando en realidad es vulnerable a ciertos workflows de actualización.
Ser consciente de esta diferencia es clave para diseñar una red más robusta y predecible.
Análisis
Al inspeccionar los logs del Manager vemos que se envía el siguiente comand de netconf hacia BR1-2.
30-Jul-2025 19:34:51,103 UTC INFO [6a486f9b-e3d8-42f7-982b-89701bfeab58] [Manager01] [ChangePartitionActionProcessor] (device-action-change_partition-1) || Change partition request XML <activate xmlns="http://cisco.com/ns/yang/Cisco-IOS-XE-install-rpc">
<uuid xmlns="http://cisco.com/ns/yang/Cisco-IOS-XE-install-rpc">change_partition-fc8b8de6-5f34-470d-b8a0-40e0f6513686%C8K-D4CE7174-5261-7E6F-91EA-4926BCF4C2DD%1800000</uuid>
<version xmlns="http://cisco.com/ns/yang/Cisco-IOS-XE-install-rpc">17.15.03a.0.176</version>
</activate>
El comando equivalente en SD-WAN es:
request platform software sdwan activate <version>
Por lo tanto, no es una comparación directa, pero naturalmente se esperaría un cierre limpio de la sesión BGP como cuando se usa el comando reload.
Solución
Para evitar este comportamiento, debemos usar BFD enlazado con BGP:
Para configurarlo en los equipo de SD-WAN se hace por CLI Add-on
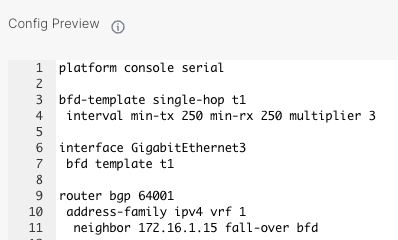
La configuración en el Gateway:
bfd-template single-hop t1
interval min-tx 250 min-rx 250 multiplier 3
interface eth0/0
bfd template t1
router bgp 64002
bgp log-neighbor-changes
neighbor 172.16.1.1 remote-as 64001
neighbor 172.16.1.1 fall-over bfd
neighbor 172.16.1.2 remote-as 64001
neighbor 172.16.1.2 fall-over bfd
Con esto, BGP detectará el fallo en menos de un segundo, previniendo ese blackhole del tráfico.
Al probarlo, solo se pierde un ping:
Gateway#ping 172.16.2.2 rep 10000000
Type escape sequence to abort.
Sending 10000000, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
*Aug 1 09:50:08.876: %BFDFSM-6-BFD_SESS_DOWN: BFD-SYSLOG: BFD session ld:1 handle:1,is going Down Reason: DETECT TIMER EXPIRED
*Aug 1 09:50:08.876: %BGP-5-NBR_RESET: Neighbor 172.16.1.2 reset (BFD adjacency down)
*Aug 1 09:50:08.876: %BGP-5-ADJCHANGE: neighbor 172.16.1.2 Down BFD adjacency down
*Aug 1 09:50:08.876: %BGP_SESSION-5-ADJCHANGE: neighbor 172.16.1.2 IPv4 Unicast topology base removed from session BFD adjacency down.!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
*Aug 1 09:50:08.876: %BFD-6-BFD_SESS_DESTROYED: BFD-SYSLOG: bfd_session_destroyed, ld:1 neigh proc:BGP, idb:Ethernet0/0 handle:1 active!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
<...>
Success rate is 99 percent (22877/22878), round-trip min/avg/max = 1/1/70 ms
Resumen: CLI vs Manager
Here’s a quick comparison of what happens when a router reloads via CLI vs when it’s upgraded through the SD-WAN Manager:
| Comportamiento | Reinicio por CLI(reload) |
Actualización via Manager |
|---|---|---|
| Manejo sesión de BGP | Sesión cerrada con TCP FIN | Sesión permanece activa hasta llegar al hold time |
| Retiro de rutas | Inmediato | Retrasado (hasta llegar al BGP hold timer) |
| Impacto en el tráfico | Mínimo | Alto (blackhole) |
| Cubierto en pruebas típicas | Sí | No siempre |
| ¿Puede mitigarse con BFD? | Opcional | Altamente recomendado |
| Convergencia sin BFD) | sub-segundo | Minutos |
| Convergencia con BFD) | sub-segundo | Sub-segundo |
Esta tabla resalta por qué BFD no es solo “algo bueno de tener”, sino una parte crítica en las implementaciones de SD-WAN.
Conclusion
Este caso de estudio revela un aspecto importante y frecuentemente pasado por alto del comportamiento ante fallos en Cisco SD-WAN: no todos los reinicios son tratados por igual. Mientras que un reinicio manual termina limpiamente las sesiones BGP, provocando un redireccionamiento inmediato, una actualización iniciada desde el SD-WAN Manager no siempre envía señales a los protocolos de control antes de apagarse. Esta diferencia sutil puede causar pérdida de tráfico (blackhole) durante toda la duración del hold timer de BGP.
Aquí es donde BFD se vuelve un aliado clave. Al reducir los tiempos de detección de fallos de minutos a sub-segundos, BFD asegura que los protocolos de enrutamiento puedan adaptarse rápidamente, incluso en casos donde el router no cierra adecuadamente las sesiones. Asociar BFD a las sesiones BGP es una forma simple y efectiva de reforzar tu topología frente a estos comportamientos.
Además, este comportamiento no se limita solo a actualizaciones de software. También puedes encontrar problemas similares en otros escenarios de “fallo silencioso”, por ejemplo:
- Un corte de fibra entre pares que no genera una caída directa de la interfaz.
- Fallos indirectos dentro del transporte o la infraestructura de switching.
- Un cambio de route processor (RP).
Entonces, ¿cuál es la lección principal? No asumas que el comportamiento por CLI refleja todos los escenarios. Siempre prueba el failover usando los métodos reales que se usan en producción—ya sea una actualización de software o una tarea iniciada desde el Manager. Y como recomendación final: despliega siempre BFD. Es una inversión pequeña con un gran retorno.
¡Nos vemos en el próximo!