Introduction
The idea of writing this post came after witnessing an unexpected behavior in how SD-WAN routers handle different operations that make the router reboot. In fact this was discovered “by accident” while performing software upgrades on a couple of SD-WAN routers and was not caught during failover testing. In today’s post I am going to compare how reloading a router through the reload command is treated differently than a reload triggered by a software upgrade.
Setup
A traditional dual-router SD-WAN setup, running BGP towards an external router on the service side providing connectivity to other sites. Something simple like this:
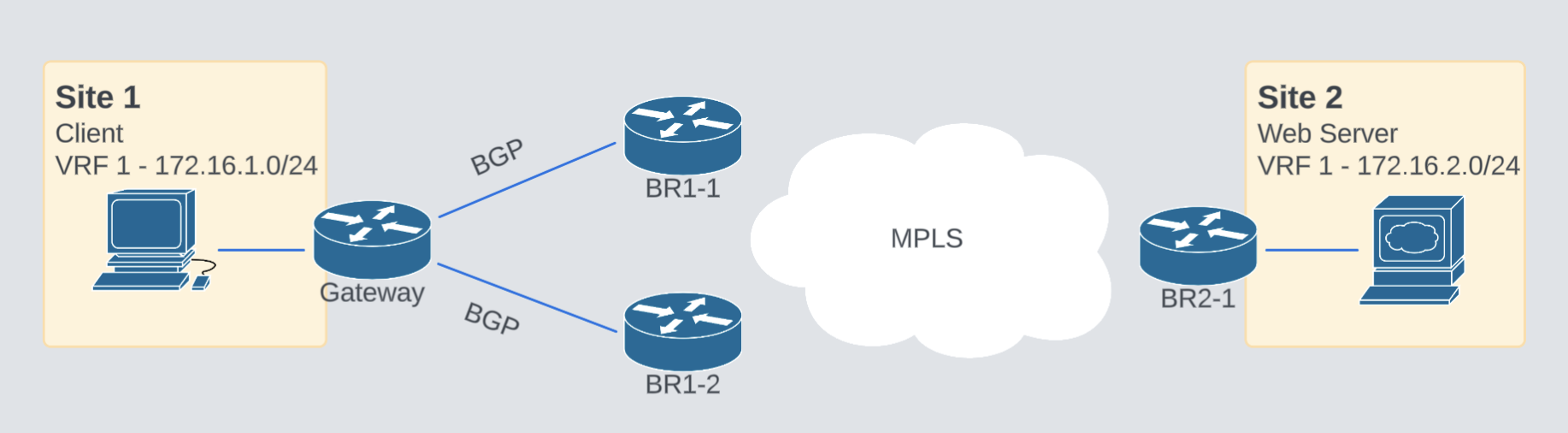
The BGP configuration is super simple and enough to exemplify this behavior. The SD-WAN routers have identical configurations.
Gateway#show run | s r b
router bgp 64002
bgp log-neighbor-changes
neighbor 172.16.1.1 remote-as 64001
neighbor 172.16.1.2 remote-as 64001
BR1-1#sh run | s r b
router bgp 64001
bgp log-neighbor-changes
!
address-family ipv4 vrf 1
network 172.16.2.0 mask 255.255.255.0
neighbor 172.16.1.15 remote-as 64002
neighbor 172.16.1.15 activate
neighbor 172.16.1.15 send-community both
distance bgp 20 200 20
exit-address-family
At a routing level, the Gateway router has two available entries to reach the web server, both equal and coming from BGP. With the current configuration, the Gateway picks BR1-1 as primary and BR1-2 will remain as backup.
Gateway# sh ip route | b Gateway
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Ethernet0/0
L 172.16.1.15/32 is directly connected, Ethernet0/0
B 172.16.2.0/24 [20/1000] via 172.16.1.1, 02:48:02
Gateway# sh ip bgp
BGP table version is 3, local router ID is 192.168.1.15
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
t secondary path, L long-lived-stale,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
* 172.16.2.0/24 172.16.1.2 1000 0 64001 i
*> 172.16.1.1 1000 0 64001 i
Behavior when using the reload command
Let’s start examining what the SD-WAN routers do when going down for reload. I will reload BR1-1 as it’s the primary router.
*18:08:35.380 UTC Wed Jul 30 2025
BR1-1#reload
Proceed with reload? [confirm]
I will start a ping from the gateway router to verify is connectivity is affected
Gateway#sh clock
*18:08:42.345 UTC Wed Jul 30 2025
Gateway#ping 172.16.2.2 rep 10000
Type escape sequence to abort.
Sending 10000, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
<...>
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
*Jul 30 18:09:01.490: %BGP-5-NBR_RESET: Neighbor 172.16.1.1 reset (Peer closed the session)
*Jul 30 18:09:01.490: %BGP-5-ADJCHANGE: neighbor 172.16.1.1 Down Peer closed the session
*Jul 30 18:09:01.490: %BGP_SESSION-5-ADJCHANGE: neighbor 172.16.1.1 IPv4 Unicast topology base removed from session Peer closed the session
<...>
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Success rate is 100 percent (10000/10000), round-trip min/avg/max = 1/1/32 ms
Gateway#sh ip route | b Gateway
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Ethernet0/0
L 172.16.1.15/32 is directly connected, Ethernet0/0
B 172.16.2.0/24 [20/1000] via 172.16.1.2, 00:02:42
Gateway#sh ip bgp all sum | b Nei
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
172.16.1.1 4 64001 0 0 1 0 0 00:00:19 Active
172.16.1.2 4 64001 193 197 4 0 0 02:51:15 1
We can see that the BGP session to BR1-1 was closed and the ping continued without issues through BR1-2.
Looking at the packet level, BR1-1 closed the BGP session right before reloading, preventing any connectivity issues.

This is the usual expected behavior and the way most of the failover testing is conducted.
Behavior when router reloads due to upgrade
After that first reload, BR1-2 is now marked as primary path.
BGP#sh ip route | b Gateway
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Ethernet0/0
L 172.16.1.15/32 is directly connected, Ethernet0/0
B 172.16.2.0/24 [20/1000] via 172.16.1.2, 00:28:48
This time I will use the Manager to upgrade BR1-2 to see what happens.
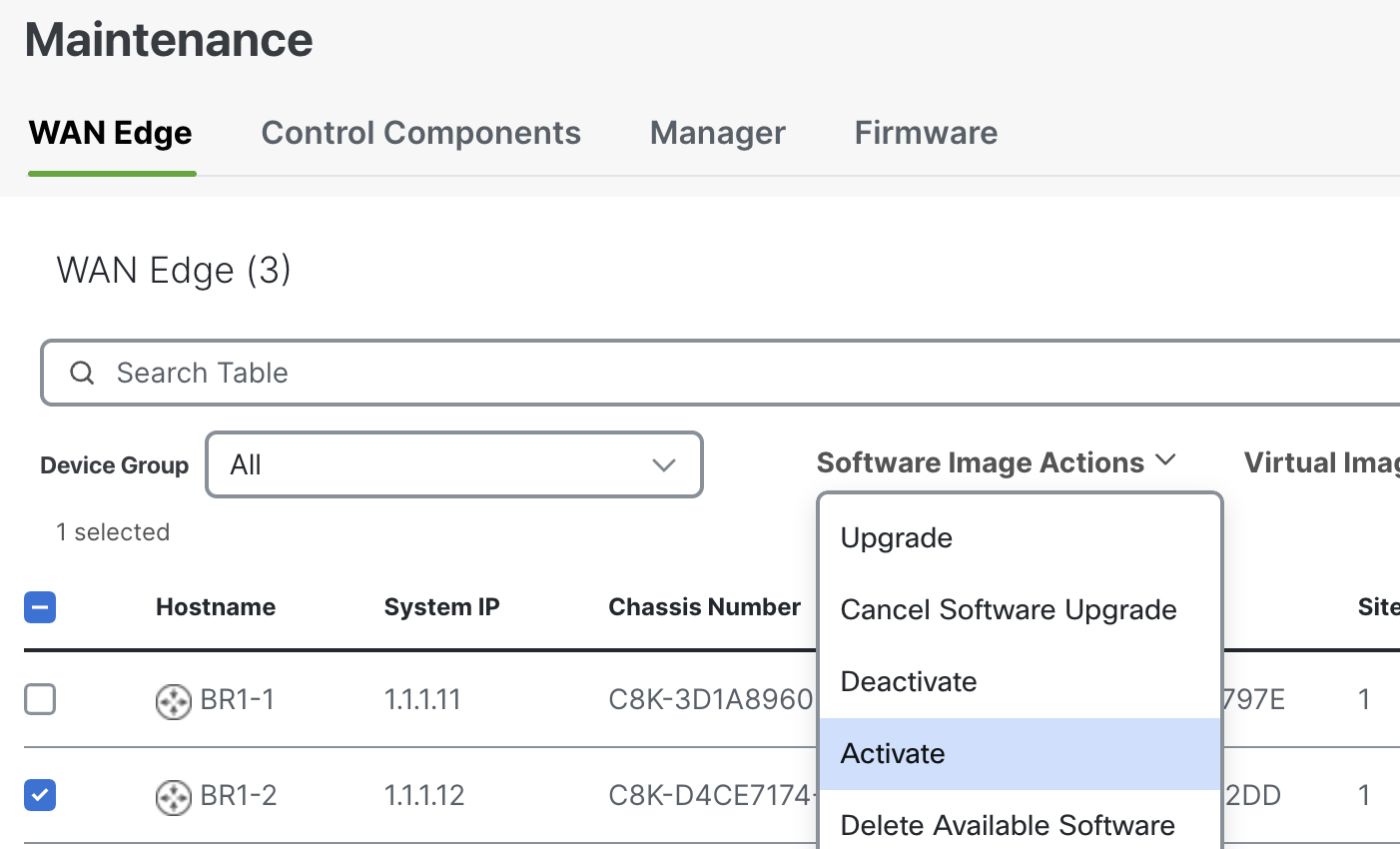
Ping from the Gateway router fails once BR1-2 goes down for reload.
Gateway# ping 172.16.2.2 rep 1000000
Type escape sequence to abort.
Sending 1000000, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!............................................
Interestingly, the BGP neighbor is still up and, as a consequence, the route is still pointing to BR1-2 that is no longer available!
Gateway# sh ip route | b Gate
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Ethernet0/0
L 172.16.1.15/32 is directly connected, Ethernet0/0
B 172.16.2.0/24 [20/1000] via 172.16.1.2, 00:35:09
Traffic is blackholed for the entire duration of the BGP hold time
Gateway# ping 172.16.2.2 rep 5
Type escape sequence to abort.
Sending 10, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
.....
*Jul 30 15:17:10.575: %BGP-3-NOTIFICATION: sent to neighbor 172.16.1.2 4/0 (hold time expired) 0 bytes
Success rate is 50 percent (5/10), round-trip min/avg/max = 1/1/2 ms
*Jul 30 15:17:10.575: %BGP-5-NBR_RESET: Neighbor 172.16.1.2 reset (BGP Notification sent)
*Jul 30 15:17:10.575: %BGP-5-ADJCHANGE: neighbor 172.16.1.2 Down BGP Notification sent
*Jul 30 15:17:10.575: %BGP_SESSION-5-ADJCHANGE: neighbor 172.16.1.2 IPv4 Unicast topology base removed from session BGP Notification sent
Gateway#ping 172.16.2.2 rep 5
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/3 ms
Common Misconceptions
One common misconceptions in network operations is that all forms of reboot behave the same. It’s easy to assume that whether a router reboots because of a reload command, power cycle, or software upgrade, the result should be consistent: BGP session drops, routes get withdrawn, traffic fails over.
This case study proves otherwise.
In Cisco SD-WAN, a reload initiated through the Manager during an image upgrade does not gracefully close control plane sessions like BGP. Unlike a CLI-based reload where the router sends TCP FIN packets to terminate sessions cleanly, the upgrade-triggered reload skips that step — keeping the BGP session “alive” on the peer side, even when the router is already offline.
This subtle behavior is rarely documented, and even less frequently tested. Many engineers rely solely on reload or interface flap tests to validate failover behavior. As a result, they may believe their setup is resilient, when in fact it’s vulnerable to specific upgrade workflows.
Being aware of this distinction is key to designing a more robust and predictable network.
Analysis
Inspecting the Manager’s log we can see the following netconf command getting applied to BR1-2.
30-Jul-2025 19:34:51,103 UTC INFO [6a486f9b-e3d8-42f7-982b-89701bfeab58] [Manager01] [ChangePartitionActionProcessor] (device-action-change_partition-1) || Change partition request XML <activate xmlns="http://cisco.com/ns/yang/Cisco-IOS-XE-install-rpc">
<uuid xmlns="http://cisco.com/ns/yang/Cisco-IOS-XE-install-rpc">change_partition-fc8b8de6-5f34-470d-b8a0-40e0f6513686%C8K-D4CE7174-5261-7E6F-91EA-4926BCF4C2DD%1800000</uuid>
<version xmlns="http://cisco.com/ns/yang/Cisco-IOS-XE-install-rpc">17.15.03a.0.176</version>
</activate>
The SD-WAN equivalent of the command is:
request platform software sdwan activate <version>
So, in reality, this is not an apple to apple comparison, but it’s natural to expect the BGP session being closed just as it happened with the reload command.
Solution
To overcome this situation, we can simply configure BFD and tie it to the BGP session:
On the SD-WAN devices we should use a CLI add-on.
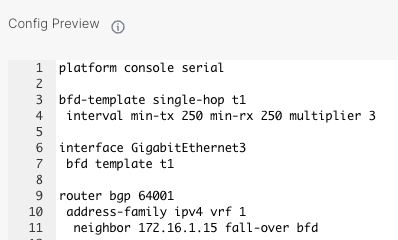
Config on the Gateway:
bfd-template single-hop t1
interval min-tx 250 min-rx 250 multiplier 3
interface eth0/0
bfd template t1
router bgp 64002
bgp log-neighbor-changes
neighbor 172.16.1.1 remote-as 64001
neighbor 172.16.1.1 fall-over bfd
neighbor 172.16.1.2 remote-as 64001
neighbor 172.16.1.2 fall-over bfd
By doing so, the BGP session is tracked and issues can be detected in less than a second, preventing blackholing the traffic when upgrading the device.
Testing with BFD configured, only one ping is lost
Gateway#ping 172.16.2.2 rep 10000000
Type escape sequence to abort.
Sending 10000000, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
*Aug 1 09:50:08.876: %BFDFSM-6-BFD_SESS_DOWN: BFD-SYSLOG: BFD session ld:1 handle:1,is going Down Reason: DETECT TIMER EXPIRED
*Aug 1 09:50:08.876: %BGP-5-NBR_RESET: Neighbor 172.16.1.2 reset (BFD adjacency down)
*Aug 1 09:50:08.876: %BGP-5-ADJCHANGE: neighbor 172.16.1.2 Down BFD adjacency down
*Aug 1 09:50:08.876: %BGP_SESSION-5-ADJCHANGE: neighbor 172.16.1.2 IPv4 Unicast topology base removed from session BFD adjacency down.!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
*Aug 1 09:50:08.876: %BFD-6-BFD_SESS_DESTROYED: BFD-SYSLOG: bfd_session_destroyed, ld:1 neigh proc:BGP, idb:Ethernet0/0 handle:1 active!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
<...>
Success rate is 99 percent (22877/22878), round-trip min/avg/max = 1/1/70 ms
CLI vs Manager Behavior Summary
Here’s a quick comparison of what happens when a router reloads via CLI vs when it’s upgraded through the SD-WAN Manager:
| Behavior | CLI reload | SD-WAN Manager Upgrade |
|---|---|---|
| BGP Session Handling | Session closed gracefully (TCP FIN) | Session remains open until timeout |
| Route Withdrawal on Peer Router | Immediate | Delayed (until BGP hold timer expires |
| Impact on Traffic | Minimal (instant failover) | High (traffic blackholed) |
| Seen During Traditional Testing? | Yes | Often overlooked |
| Can Be Mitigated with BFD? | Optional | Strongly recommended |
| Time to Convergence (w/o BFD) | sub-second | Minutes |
| Time to Convergence (with BFD) | sub-second | Sub-second |
This table highlights why BFD is not just a “nice-to-have” but a critical part of SD-WAN deployments.
Conclusion
his case study reveals an important and often overlooked aspect of failover behavior in Cisco SD-WAN: not all reboots are treated equally. While a manual reload cleanly terminates BGP sessions—prompting immediate rerouting—an upgrade triggered via SD-WAN Manager does not always signal the control protocols before going offline. This subtle distinction can cause traffic being blackholed for the full duration of the BGP hold timer.
This is where BFD becomes a key ally. By reducing failure detection times from minutes to sub-second, BFD ensures that routing protocols can adapt quickly—even in cases where the router doesn’t properly close sessions. Tying BFD to BGP sessions is a simple and effective way to harden your topology against these behaviors.
Moreover, this behavior isn’t limited to software upgrades. You may also encounter similar issues in other “silent failure” scenarios—for example:
- A fiber cut between peers that doesn’t result in a direct interface down.
- Indirect failures within the transport or switching infrastructure.
- A route processor (RP) swap
So, what’s the main takeaway? Don’t assume CLI behavior reflects all scenarios. Always test failover using the actual methods used in production—whether that’s a software upgrade or Manager-initiated task. And as a final recommendation, always deploy BFD. It’s a small investment with a big payoff.